Czym jest deduplikacja?
Deduplikacja danych to proces, który eliminuje nadmierne ilości kopii danych, znacząco zmniejszając wymagania pojemności storage.
Proces ten może być realizowany w momencie zapisywania danych do systemu (deduplikacja inline), lub jako proces dziejący się w tle, który eliminuje duplikaty już po zapisie danych na dyski.
W NetApp, deduplikacja jest technologią z zerową utratą danych, która może działać jednocześnie jako proces inline, oraz postprocesingowo po zapisie, aby zmaksymalizować ilość deduplikowanych danych.
Macierze NetApp All Flash, mają domyślnie włączoną deduplikację – wydajność macierzy gwarantuje deduplikację inline bez jakiejkolwiek utraty płynności działania systemów produkcyjnych.
Obciążenie wydajności związane z deduplikacją jest minimalne, ponieważ działa ona w dedykowanej dla siebie domenie, która jest całkowicie oddzielona od systemów klienta, niezależnie od tego jaka aplikacja jest na nich uruchomiona, lub w jaki sposób dane są udostępniane (NAS/SAN).
Jak działa deduplikacja?
Deduplikaja pracuje na blokach 4KB, na przestrzeni całego volumenu FlexVol oraz wszystkich agregatów w volumenie, pozostawiając wyłącznie unikalne dane. Opiera się ona na jednostkowych podpisach cyfrowych dla wszystkich bloków danych 4KB.
Gdy dane są zapisywane w systemie, wbudowany mechanizm deduplikacji skanuje przychodzące bloki, tworzy cyfrowy podpis i zapisuje go w specjalnej strukturze danych w pamięci.
Podpis zostaje później sprawdzany w strukturze i pamięci podręcznej i jeśli jest odnaleziony, zostaje przeprowadzone porównanie między obecnym blokiem, a blokiem dawcy, aby upewnić się, że dopasowanie jest dokładne. Podczas weryfikacji bloki zostają przypisane w metadanych jako współdzielone.
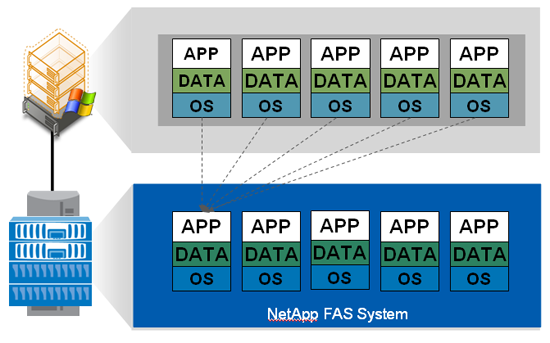
Jakie korzyści niesie za sobą deduplikacja?
- Działa na urządzeniach NetApp oraz urządzeniach firm trzecich
- Niezależna od aplikacji
- Niezależna od protokołu
- Minimalne obciążenie
- Działa na macierzach NetApp AFF, FAS, hybrid
- Sprawdzanie bezstratne Byte-by-byte
- Może być stosowana dla nowych danych, lub danych już wcześniej przechowywanych na macierzy
- Może być przeprowadzana w godzinach mniejszeo obciążenia
- Zintegrowana z innymi technologiami wydajności pamięci NetApp
- Bezpłatna
Kiedy użyć deduplikacji?
Deduplikacja jest przydatna niezależnie od typu obciążenia. Maksymalne korzyści można zaobserwować w środowiskach wirtualnych, w których wiele maszyn wirtualnych jest używanych do testowania i wdrażania aplikacji.
VDI to kolejny przykład bardzo dobrego środowiska do korzystania z deduplikacji, ponieważ ilość zduplikowane dane między komputerami jest bardzo wysoka.
Niewielki współczynnik deduplikacji uzyskamy w niektórych bazach danych takich jak Oracle i SQL, ponieważ klucze często mają unikalne klucze, przez co nie można zidentyfikować ich jako duplikatów.
Oczywiście nie wszystkie dane dają się tak samo łatwo deduplikować. Np. dane uprzednio skompresowane – zip, rar – mają bardzo niski współczynnik deduplikacji. Podobnie jest w przypdaku zdjęć JPG, oraz plików wideo mpg, div-x itp.